The beginning
Do you ever think of how to design the system of a marketplace website that allows millions of users to browse products and purchase them from start to finish? Or maybe wonder how a video streaming application like Netflix can stream so fast and show different video quality based on your internet connection speed?
Me too! and this is why I want to start writing about System Design.
Why System Design is important?
As a software engineer, it's crucial to understand System Design because it is the backbone of any project and application.
To advance our careers as software engineers and deliver long-term solutions, we need to know how to design an application's system and how each module, storage, server, and interface work together.
Especially when it comes to designing a system that supports millions of users. It can be challenging because it requires us to continuously improve and refine our strategy.
The best part is there are no "right" answers. Based on the project's requirements, which could always be dynamic and ever-changing, we can explore different solutions that satisfactorily fit the criteria.
So let's dive into it and have fun!
What is System Design?
System design is the process of defining a system's entire requirements, such as the architecture, modules, interface, and design.
To be able to design a large and complex system, we need to start with the most basic setup.
Single server setup
Let's start with the simplest setup, a single server setup. A single server setup is where everything (web, app, database, cache) runs on one server.
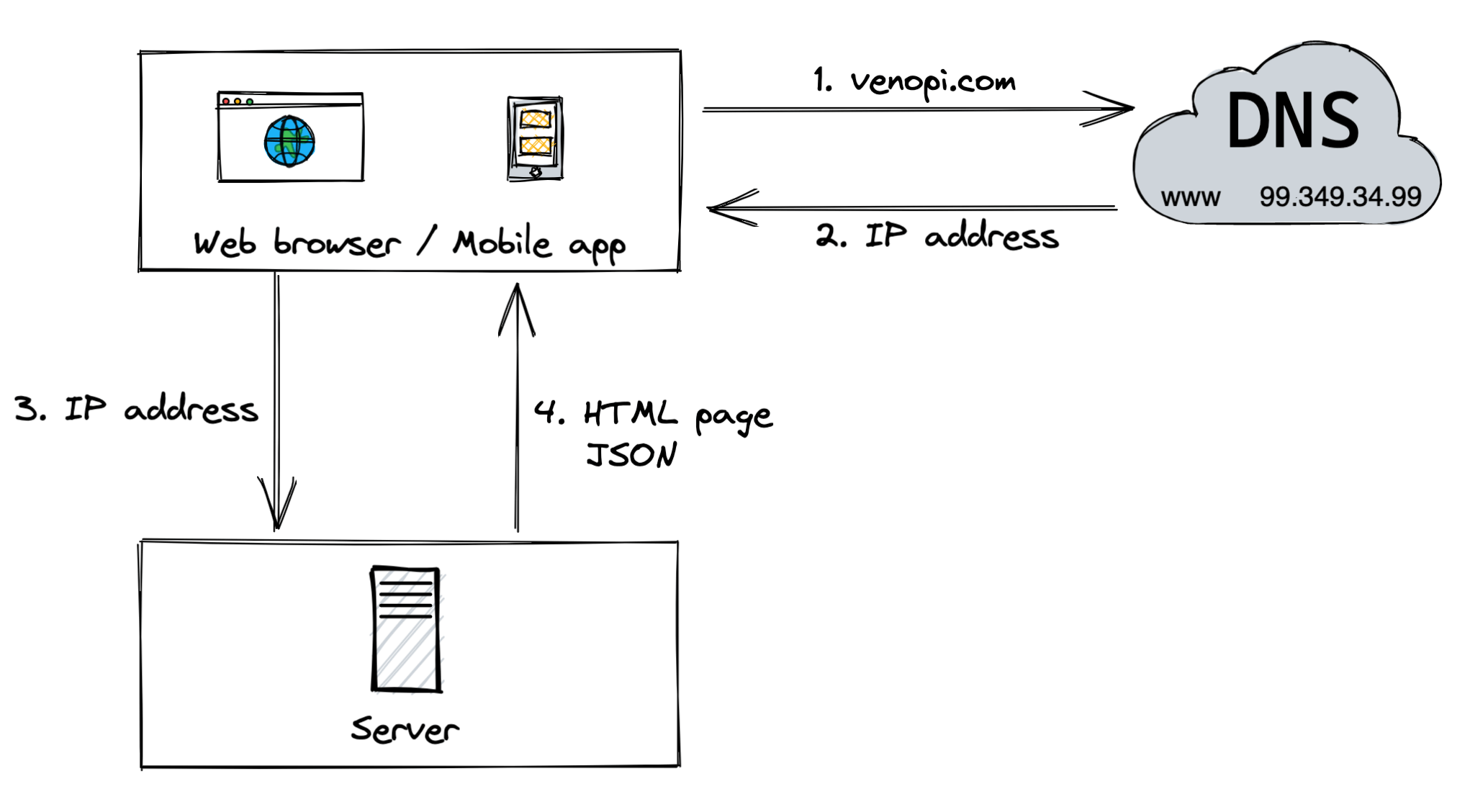
The flow is like this:
-
1
Users access the website via the domain name (www.venopi.com).
The Domain Name System (DNS) is a paid service provided by third parties that translates domain names (like www.venopi.com) into IP addresses (like 99.349.34.99) so browsers can load Internet resources.
-
2
IP address is returned from the DNS to the browser or mobile app.
-
3
Once the IP address is received, Hypertext Transfer Protocol (HTTP) requests are sent directly to our web server.
-
3
The web server returns HTML or JSON response for rendering.
Now we have received an HTML page on our Web browser or JSON on our Mobile app. What's next?
Database
When the users are growing, more than one server is needed. We will need at least one server for the traffic (web and mobile) and the other for the database.
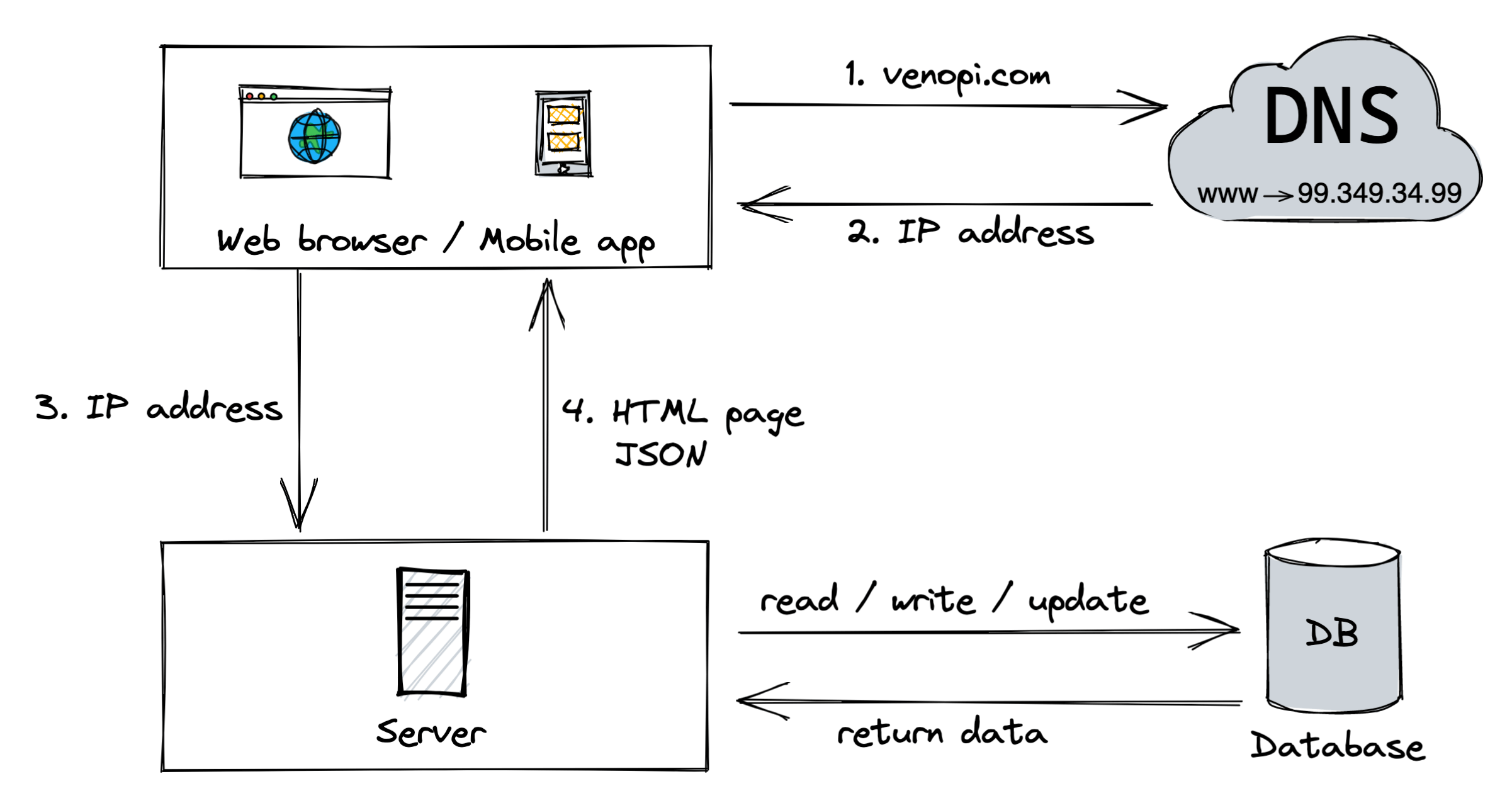
There are two different kinds of databases: a relational database and a non-relational database.
Relational databases
Relational databases are known as relational database management system (RDBMS). It represents and stores data in tables and rows. You can join operations using SQL across different database tables. MySQL, PostgreSQL, Oracle database, and Amazon Relational Database Service (RDS) are the most popular ones.
Relational databases are the most commonly used ones. It's been around since the 70s and has proven to work well.
Relational databases could be the right choice if:
- The application works with related data.
- The need to have a database instance automatically refreshes when one user updates a specific record and provides that information in real-time.
- The application cares about assessing data integrity.
- The application prioritises vertical scaling over horizontal scaling.
Non-Relational databases
Non-Relational databases are called NoSQL databases. These databases are grouped into four categories: key-value stores, graph stores, column stores, and document stores. Join operations are generally not supported. The most popular ones are MongoDB, Cassandra, and Couchbase.
Non-Relational databases could be the right choice if:
- The application requires super-low latency.
- The data is unstructured or has no relational data.
- The purpose is to serialise and deserialised data (JSON, XML, YAML).
- The need to store a massive amount of data.
- The application prioritises availability over consistency.
Scaling
Scaling is a common system problem when your application grows (more users, more orders, etc.).
There are two different types of scaling, vertical and horizontal.
Vertical means adding more power to the existing server (RAM, CPU).
Horizontal means adding more servers next to your existing one.
Load balancer
A load balancer is a device between the user and the servers to ensure that no server is overworked by evenly distributing traffic to maximise speed and performance.
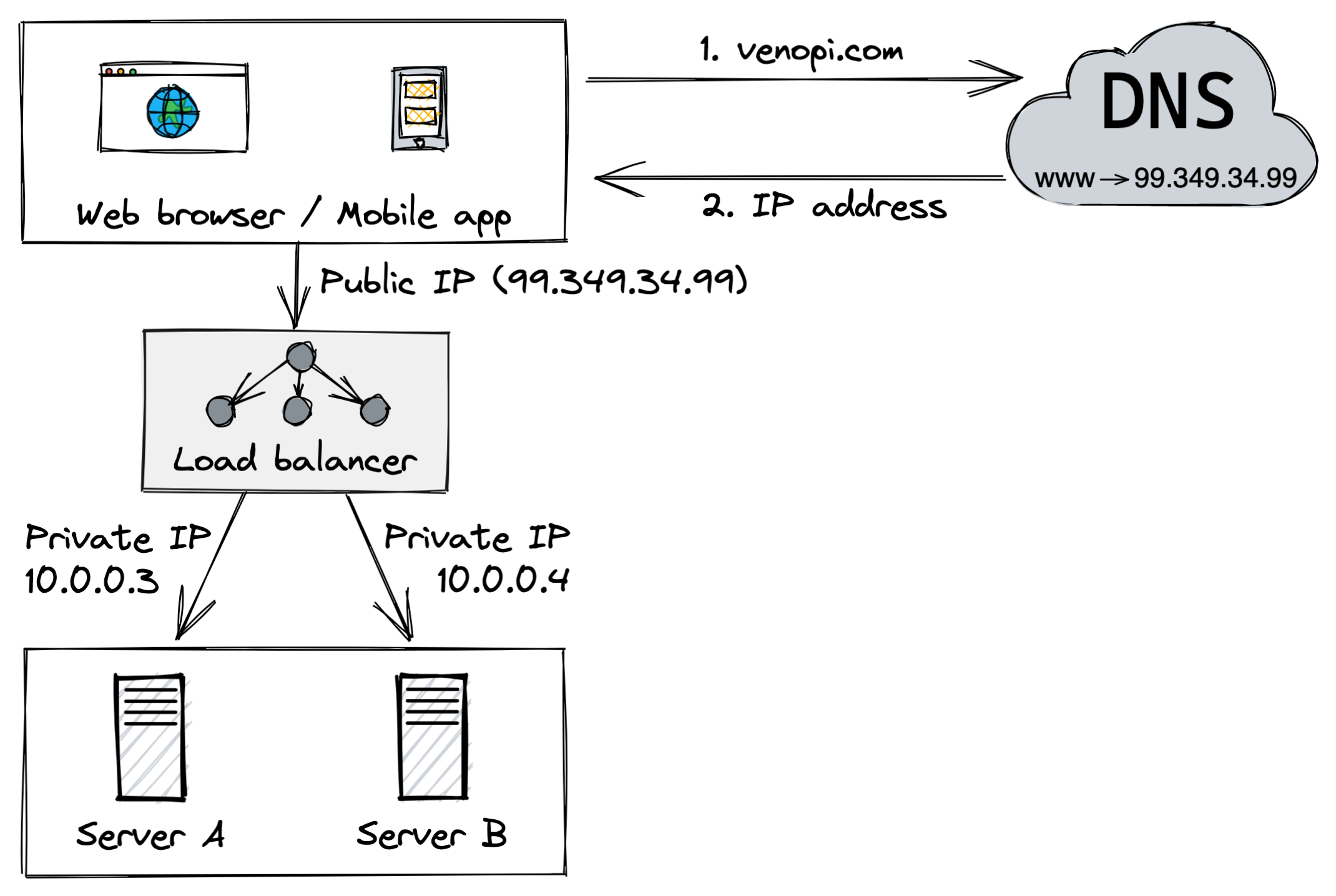
As shown above, users connect to the public IP of the load balancer instead of the web server. Then the load balancer communicates with the web servers via private IPs. The private IPs are used for communication between servers in the same network and are unreachable over the internet.
The nice part about this approach is that if server A goes down, all the traffic will be routed to server B. This means that the application is always gonna be online.
If the traffic proliferates and two servers are no longer enough to handle it. We can add more servers, and the load balancer can handle it gracefully by automatically sending requests or traffic to them.
The web tier looks solid now. How about the database, though? We currently only have one. Is it enough, or can we improve the data tier?
Database replication
Yep! It is as it sounds. It's a method where we replicate the primary database (original) and create read replicas (copies) from it.
The primary database usually only supports the write operations, while the read replicas support the read operations. Any actions related to data modification (insert, delete, update) must only be sent to the primary.
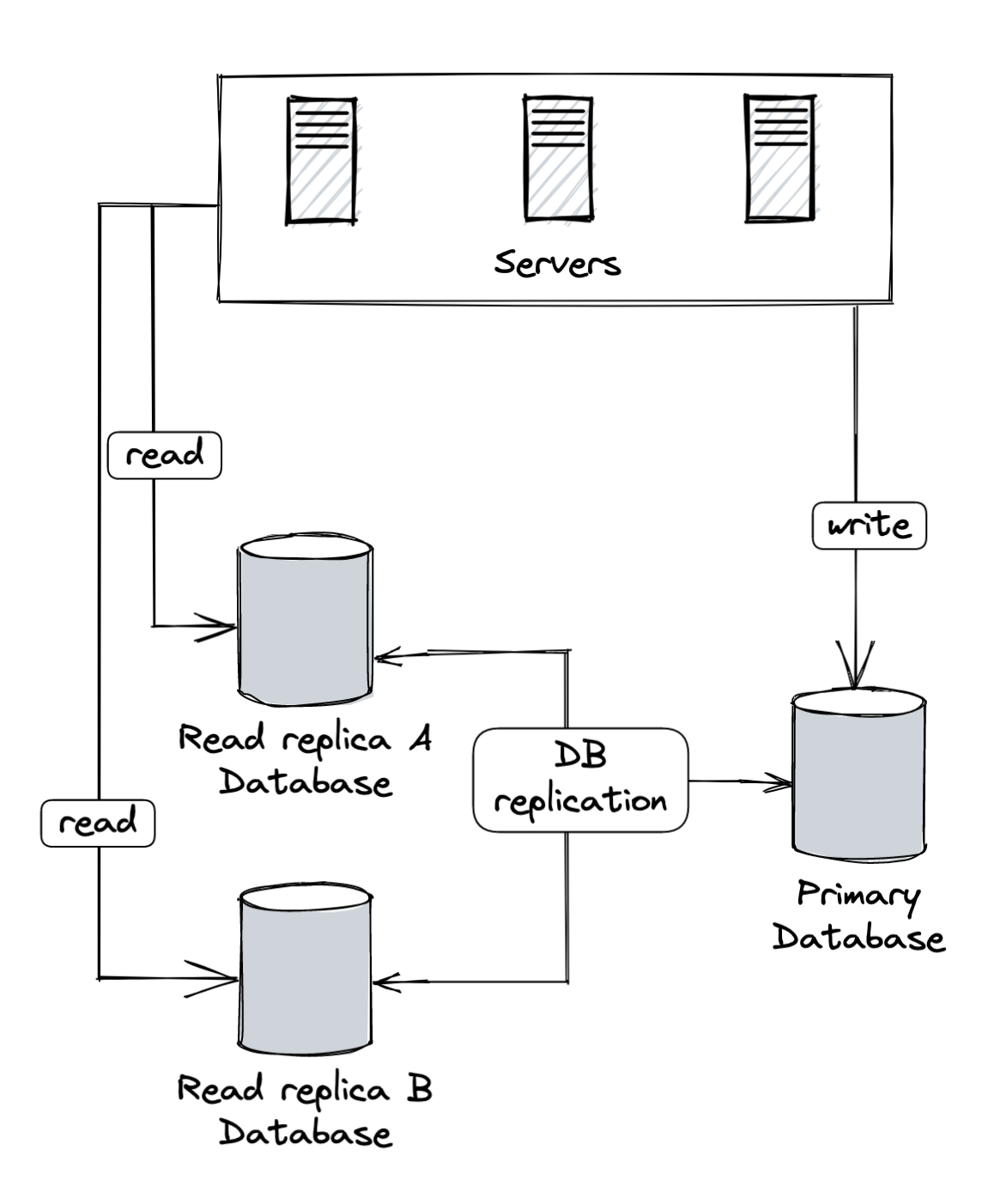
So now we have the primary database and several read replicas, what if one of the databases goes offline?
-
If there is only one read replica and it's offline
The read operations will be directed to the primary temporarily. Once the issue is found, a new read replica database will replace the old one.
-
If there are multiple read replicas and one of them is offline
The read operations will be directed to other healthy read replicas. Once the issue is found, a new read replica database will replace the old one.
-
If the primary is offline
A read replica database will be promoted to be the primary. Then all the database operations will be temporarily executed on the new primary. A new read replica database will immediately replace the old one for data replication.
Our data tier looks solid now! What are the benefits of database replication?
-
Higher reliability and availability
The data will still be available even if one of the machines has a severe hardware failure because there are many replications across different locations. Spinning up a new database will be trivial.
-
Better data security
Many replications across different locations also mean that the data will be safe on some servers, even if a disaster occurs on others.
-
Performance improvement
The model improves performance because the data is distributed on different servers. The primary is responsible for data modification, while read replicas are responsible for read operations.
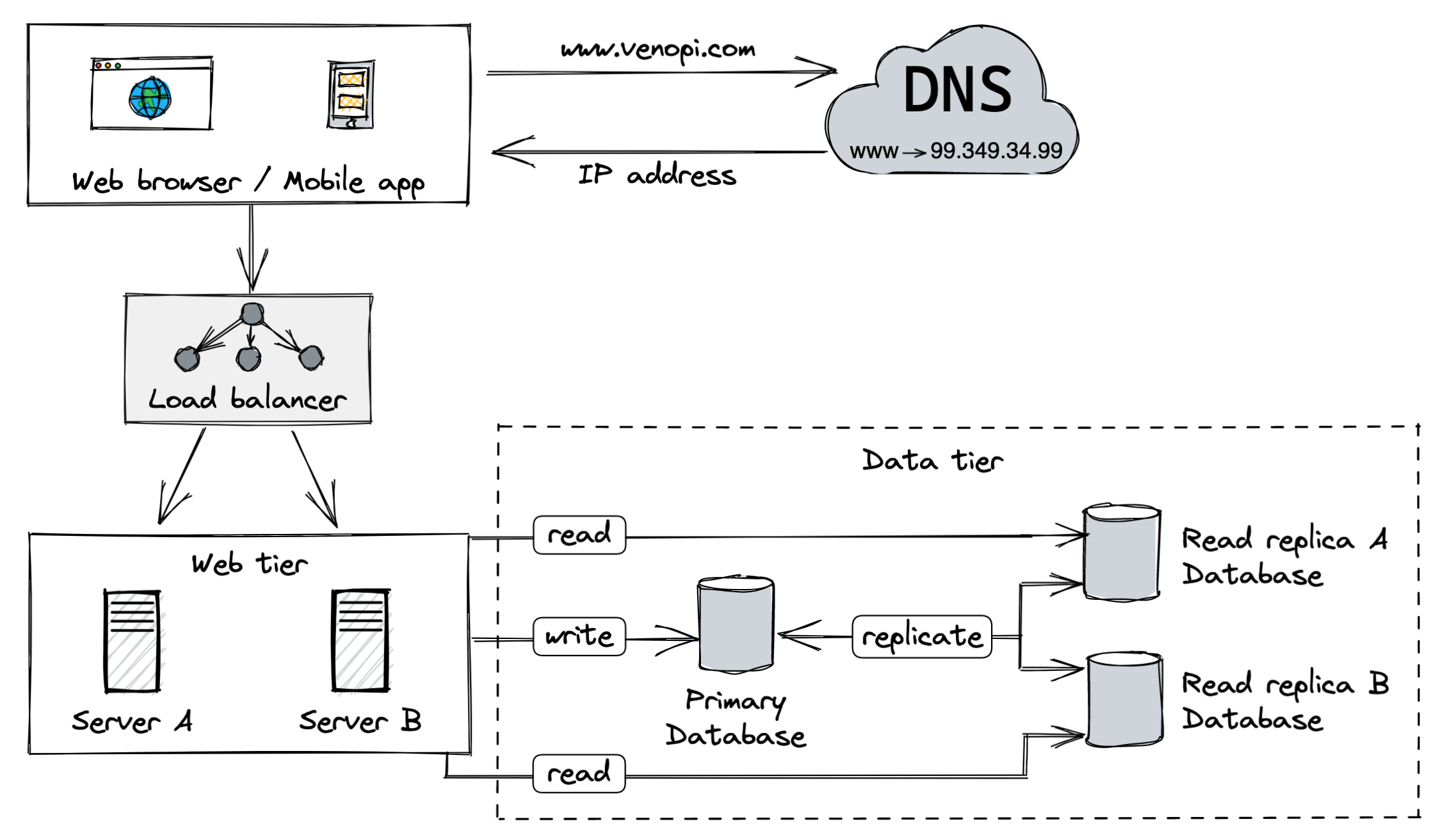
Let's go through it together:
-
Users get the public IP address of the load balancer from the DNS.
-
Users connect to the load balancer with the public IP address.
-
The HTTP request is routed to either server A or server B.
-
The web server (A/B) reads the data from one of the read replica databases.
-
The web server (A/B) routes data-modification operations to the primary database.
We now have a concrete understanding of how the web and data tier works. Let's talk about improving the load and response time.
Yes, we are talking about adding a cache layer and shifting static content to the CDN 👍
Cache
A component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere.
Multiple calls are executed every time a web page loads to fetch the data. The application performance is significantly affected by calling the database repeatedly, and the cache can mitigate this issue.
Cache tier
The cache tier is a temporary data store layer that is much faster than the database. Having a cache tier can improve the system performance by reducing the database workload.
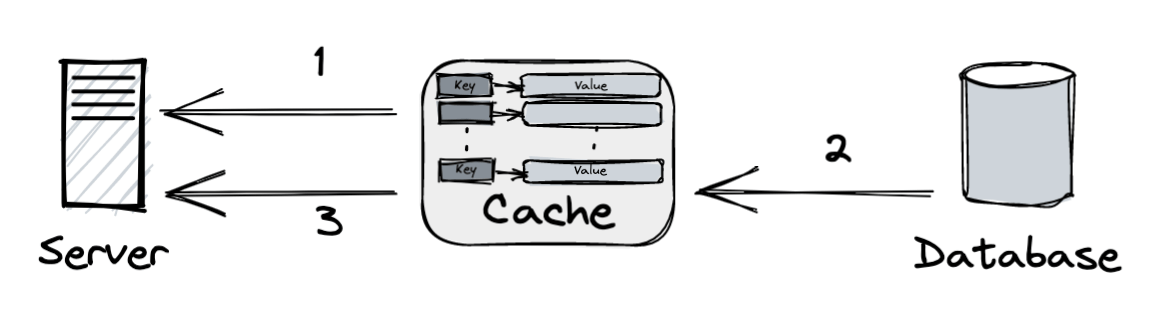
-
1
When a request is received, the web server checks if the cache has the response. If it has, it sends the data back to the client.
-
2
If not, it queries the database and stores the response in the cache.
-
3
From the cache, sends the response to the client.
Some tips when using the cache system:
- Use cache when the data is read often but rarely modified. Cached data is stored in volatile memory. It will be gone if the cache server restarts, so important data should be saved in the persistent data stores.
- Implement an expiration policy. If not implemented, the cache data will be stored permanently in the memory. It's a good practice to clean up when data is expired.
- Implement the eviction policy. When the cache is full, existing items might be removed when new items are attempted to be added. Some variations of the cache eviction policy are Last Recently Used (LRU), Last Frequently Used (LFU), First In First Out (FIFO).
- Synchronize the data and the cache correctly. Maintaining consistency is very challenging when the product grows, and there are multiple caches and databases. A good read for this topic is Scaling Memcache at Facebook.
- Avoid Single Point Of Failure (SPOF) at any cost.
Content Delivery Network (CDN)
CDN is a geographically distributed group of servers that work together to provide fast delivery of static content, such as images, stylesheets, javascript files, etc.
The way CDN work is straightforward. The further the users are located from the CDN server, the longer they will get data. Say if the CDN server is located in Amsterdam, users in Sweden will get the content faster than those in Canada.
The flow of CDN:
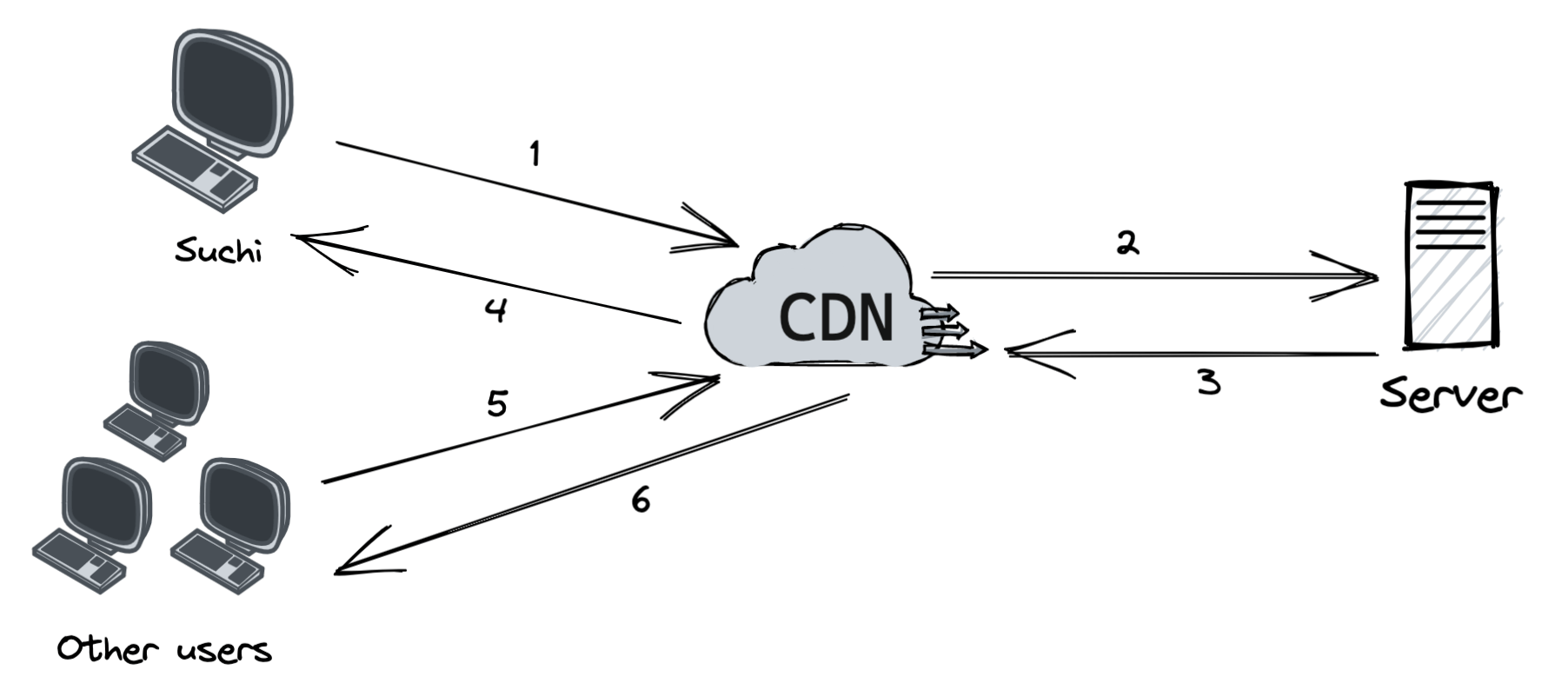
-
1
Suchi gets an image logo on Venopi. The CDN provider provides the URL's domain, such as: `https://venopi.cdnproviderx.net/logo.png`.
-
2
If the CDN server doesn't have the logo in the cache, the CDN server requests the file from the origin, which can be a web server or online storage.
-
3
The origin returns the logo to the CDN server, including the optional HTTP header Time-to-Live (TTL), which describes how long the image is cached.
-
4
The CDN caches the logo and returns it to Suchi. The image remains cached in the CDN until the TTL expires.
-
5
Other users visit venopi.com and request to get the logo.
-
6
Other users will get the logo from the cache for as long as the TTL is not expired.
Some tips when using CDN:
- CDNs are charged per data transfer in and out of the CDN. You need to pay extra for this service. However, this doesn't necessarily mean that your total cost will increase. A CDN reduces the traffic to the origin; thus, you can use smaller servers.
- CDN increases security by detecting issues and blocking traffic earlier and increases the reliability and availability of the application. Even if the origin goes offline, users can get the cached version. More uptime means more revenue.
- Implement an expiration cache policy. Not too long but also not too short ("lagom" in Swedish). If it's too long, the content may not be fresh; if it's too short, it can cause repeat reloading of content from origin servers to the CDN.
-
Implement the fallback in case of CDN failures. If CDN fails, clients should detect the problem and request resources from either other CDNs or the origin.
Most media companies use multiple CDNs instead of falling back to the origin, but this setup is overkill if the application only needs a simple setup. - Remove unused files by invalidating them before the expiration date. This can be done by using the CDN vendors' APIs or using object versioning to serve a different version of the object. It looks like `https://venopi.cdnproviderx.net/logo.png?v=2` — which the `?v=2` indicates version #2.
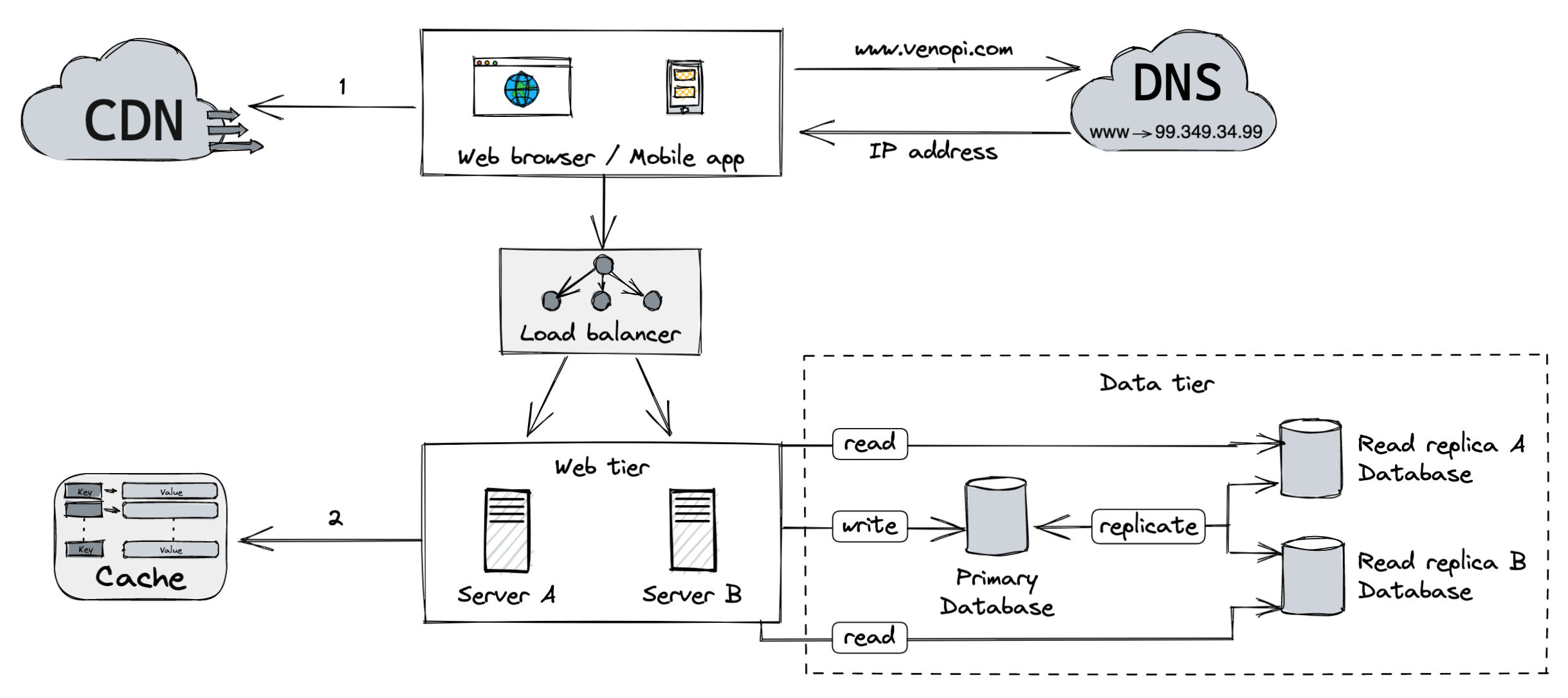
-
1
Static assets (javascript files, images, videos, stylesheets, etc) are fetched from the CDN for better performance.
-
1
The database load is reduced by the cache tier.
That's it for now!
I hope this post will help you understand better about System Design. I will write more about system design in the future, such as data center, stateless vs stateful architecture, message queues, sharding, three-tier architecture etc.
Feel free to ping me if you have any questions or suggestions 🌈
Special thanks to Ioannis Lioupras (he/him) who gave me inputs with the naming (Primary/Read replica(s)), CDN cost review, and how the majority of the media companies use multiple CDNs instead of falling back to origin 🙏